| RACH |
| What is the most tricky part in device troubleshooting ? My experience says “If a problem happens in the middle of doing something, it is relatively easy to find the root cause and troubleshoot it (probably I might have over-simplified the situation -:), but if something happened before anything started, it would be a nightmare.” For example, you set the all the parameters at thenetwork emulator for a UE you want to test and then turned on the UE. In a several second UE start booting and then in a couple of second you see a couple of antenna bars somewhere at the top of UE screen.. and then in several seconds you see ‘SOS’ or ‘Service Not Available’ in stead of your network operator name displayed on your screen and normal Antenna bars. This is what I mean by “problem in the middle of doing something”. In this case, if you collect UE log and equipment log, at least you can easily pin point out the location the problem happens and start from there for further details. But what if you are in this situation ? you set the all the parameters at the network emulator side and turn on the UE.. UE start booting up .. showing the message saying “Searching Network ….” and got stuck there.. with no Antenna bars .. not even ‘SOS’ .. just saying “No service”. And I collected UE side log and Network Emulator side log, but no signalling message. This is where our headache starts.
As examples, i) What if you don’t see ‘RRC Connection Request’ when your turned on the WCDMA UE ? ii) What if you don’t see ‘Channel Request’ when your turned on the GSM UE ? iii) What if you don’t see ‘RACH Preamble’ when your turned on the LTE UE ? First thing you have to do is to understand the every details of this procedure not only in the higher signaling layer, but also all the way down to the physical layers related to these first step. And also you have to use proper equipment which can show these detailed process. If you have an equipment that does not provide the logging or it provides log but only higher layer singnaling log, it will be extremly difficult to troubleshoot. Given that you have the proper tools, the next thing you have to be ready is to understand the detailed knowledge of these process. Without the knowledge, however good tools I have it doesn’t mean anything to me. So ? I want to teach myself here about the first step of LTE signaling which is RACH process. (Somebody would say there are many of other steps even before the RACH, like frequency Sync, Time Sync, MIB/SIB decoding.. but it put these aside for now.. since it is more like baseband processing).
It would be helpful to understand if you think about when ‘RRC Connection’ happens (or when PRACH process happens if you are interested in lower layer stuffs) in WCDMA. It would also be helpful if you think about when ‘Channel Request’ happens in GSM UE. My impression of LTE RACH process is like the combination of PRACH process (WCDMA) and Channel Request (GSM). It may not be 100% correct analogy.. but anyway I got this kind of impression. In LTE, RACH process happens in following situation (3GPP specification, 10.1.5 Random Access Procedure of 36.300 ) i) Initial access from RRC_IDLE ii) RRC Connection Re-establishment procedure iii) Handover iv) DL data arrival during RRC_CONNECTED requiring random access procedure E.g. when UL synchronisation status is “non-synchronised” v) UL data arrival during RRC_CONNECTED requiring random access procedure E.g. when UL synchronisation status is “non-synchronised” or there are no PUCCH resources for SR available. vi) For positioning purpose during RRC_CONNECTED requiring random access procedure; E.g. when timing advance is needed for UE positioning Two types of RACH process : Contention-based and Contention-free When a UE transmit a PRACH Preamble, it transmits with a specific pattern and this specific pattern is called a “Signature”. In each LTE cell, total 64 preamble signatures are available and UE select randomly one of these signatures. UE select “Randomly” one of these signatures ? Does this mean that there is some possibility that multiple UEs send PRACH with identical signatures ? Yes. There is such a possibility. It means the same PRACH preamble from multipe UE reaches the NW at the same time.. this kind of PRACH collision is called “Contention” and the RACH process that allows this type of “Contention” is called “Contention based” RACH Process. In this kind of contention based RACH process, Network would go through additional process at later step to resolve these contention and this process is called “Contention Resolution” step.
But there is some cases that these kind of contention is not acceptable due to some reason (e.g, timing restriction) and these contention can be prevented. Usually in this case, the Network informs each of the UE of exactly when and which preamble signature it has to use. Of course, in this case Network will allocate these preamble signature so that it would not collide. This kind of RACH process is called “Contention Free” RACH procedure. To initiate the “Contention Free” RACH process, UE should be in Connected Mode before the RACH process as in Handover case. Typical ‘Contention Based’ RACH Procedure is as follows : i) UE –> NW : RACH Preamble (RA-RNTI, indication for L2/L3 message size) ii) UE <– NW : Random Access Response (Timing Advance, T_C-RNTI, UL grant for L2/L3 message) iii) UE –> NW : L2/L3 message iv) Message for early contention resolution Now let’s assume that a contention happened at step i). For example, two UEs sent PRACH. In this case, both of the UE will recieve the same T_C-RNTI and resource allocation at step ii). And as a result, both UE would send L2/L3 message through the same resource allocation(meaning with the same time/frequency location) to NW at step iii). What would happen when both UE transmit the exact same information on the exact same time/frequency location ? One possibility is that these two signal act as interference to each other and NW decode neither of them. In this case, none of the UE would have any response (HARQ ACK) from NW and they all think that RACH process has failed and go back to step i). The other possibility would be that NW could successfully decode the message from only one UE and failed to decode it from the other UE. In this case, the UE with the successful L2/L3 decoding on NW side will get the HARQ ACK from Network. This HARQ ACK process for step iii) message is called “contention resolution” process. Typical ‘Contention Free’ RACH Procedure is as follows : i) UE <–NW : RACH Preamble Assignment ii) UE –> NW : RACH Preamble (RA-RNTI, indication for L2/L3 message size) iii) UE <–NW : Random Access Response (Timing Advance, C-RNTI, UL grant for L2/L3 message) Exactly when and Where a UE transmit RACH ? To answer to this question, you need to refer to 3GPP specification TS36.211 – Table 5.7.1-2.
Did you open the specification now ? It shows exactly when a UE is supposed to send RACH depending on a parameter called “PRACH Configuration Index”. For example, if the UE is using “PRACH Configuration Idex 0”, it should transmit the RACH only in EVEN number SFN(System Frame Number). Is this good enough answer ? Does this mean that this UE can transmit the RACH in any time within the specified the SFN ? The answer to this question is in “Sub Frame Number” colulmn of the table. It says “1” for “PRACH Configuration Idex 0”. It means the UE is allowed to transmit RACH only at sub frame number 1 of every even SFN. Checking your understanding of the table, I will give you one question. With which “PRACH Configuration Idex”, it would be the easiest for the Network to detect the RACH from UE ? and Why ? The answer would be 14, because UE can send the RACH in any SFN and any slots within the frame. In a big picture, you should know all the dimmensions in the following diagram. (The Red rectangle is PRACH signal).
The R_Slot is determined by PRACH Configuration Index and R_length is determined by Premable format. F_offset is dermined by the following equation when the preamble format is 0~3. n_RA_PRBoffset in this equation is specified by prach-FreqOffset in SIB2. (Refer to 36.211 5.7 Physical random access channel for the details )
< FDD >
< TDD : Preamble format 0-3 >
< TDD : Preamble format 4 >
If you see the table 5.7.1-1 show above, you see the column titled as “Preamble Format”. What is the preamble format ? It is defined as following diagram.
You would see that the length of PRACH preamble varies depending on the preamble format. For example, the length of PRACH with preamble format is (3186 + 24567) Samples. (As you know, one sample (Ts) is 1/30.72 us. It is defined as 1/(15000 x 2048) seconds in 36.211 4 Frame structure).
You may ask “Why we need this kind of multiple preamble format ?”, especially “Why we need various PRACH format with different length in time ?”. One of the main reason would be that they use different preamble format depending on cell radius, but this is oversimplified answer. I want to recommend a book titled “LTE : The UMTS From Theory to Practice” Section 19.4.2 The PRACH Structure. This is the material that describes the PRACH in the most detailed level I have ever read.
How does Network knows exactly when UE will transmit the RACH ?
It is simple. Network knows when UE will send the RACH even before UE sends it because Network tells UE when the UE is supposed to transmit the RACH. (If UE fails to decode properly the network information about the RACH, Network will fail to detect it even though UE sends RACH).
Following section will describe network informaton on RACH.
Which RRC Message contains RACH Configuration ?
It is in SIB2 and you can find the details in 3GPP 36.331.
numberOfRA-Preambles : There are total 64 RA preambles that UE can randomly choose from. But usually a cell reserve several Preambles for ‘Non-contention based’ PRACH procedure and let UE use the rest of Preambles randomly (contention based). numberOfRA-Preambles indicates how many RA preambles (RA sequences) is available for the contention based RACH process.
Following figure shows the PRACH Premable signal structure in comparison with normal Uplink subframe. A couple of points to be specially mentioned are
You don’t have to know the details of this procedure unless you are the DSP or FPGA engineer implementing LTE PHY. Just as a common sense about LTE, let’s know that PRACH is a kind of ZaddOff Chu Sequence generated by the following equation.
There are 64 preambles available for each cell and UE has to be able to generate the 64 preambles for the cell it want to camp on. You can easily generate 64 different preambles just by cyclically shifting an existing sequence, but there is a condition for this. All the preamle sequences should be authogonal to each other. Otherwise, various preambles from multiple UEs within the same cell can interfere each other. So we have to shift the generated sequence by a specifically designed value and this value is called Cv (Cyclic Shift Value) and it is defined as follows. (I think determining the Cv is one of the most complicated process in PRACH preamble generation because it gets involved with so many different parameters in cascading manner).
First, you would notice that we use different process to calculate Cv depending on whether we use ‘unrestricted sets’ or ‘restricted sets’. This decision is made by ‘Highspeedflag’ information elements in SIB2. If Highspeedflag is set to be TRUE, we have to use ‘restricted sets’ and if Highspeedflag is false, we have to use ‘unrestricted sets’. N_cs is specified by zeroCorrelationZoneConfig information elements in SIB2. As you see in this mapping, N_cs values also gets different depending on whether we use ‘restricted sets’ or ‘unrestricted sets’.
Now let’s look at how we get Nzc. This is pretty straightforward. Nzc is determined by the following table.
If the Preamble is using the unrestricted sets, it is pretty simple. You only have to know Nzc, Ncs to figure out Cv. The problem is when the Preamble is using the ‘restricted sets’. As you see the equation above, you need to know the following 4 values to figure out Cv in ‘restricted sets’.
The problem is that the calculation of these four variable is very complicated as shown below.
You would noticed that you need another value to calculate to determine which of the three case we have to use. It is du. So we need another process to determine du.
We went through a complicated procedure just to determin one number (Cv). Once we get Cv, we can generate multiple preambles using the following function.
Anyway, now we got a PRACH Preamble sequence in hand, but this is not all. In order to transmit this data. We have to convert this data into a time domain sequence and this conversion is done by the following process.
For the whole PRACH generation procedure, please refer to 5.7.2/5.7.3 of TS 36.211.
Exactly when and where Network transmit RACH Response
We all knows that Network should transmit RACH Response after it recieved RACH Preamble from UE, but do we know exactly when, in exactly which subframe, the network should transmit the RACH Response ? The following is what 3GPP 36.321 (section 5.1.4) describes.
Once the Random Access Preamble is transmitted and regardless of the possible occurrence of a measurement gap, the UE shall monitor the PDCCH for Random Access Response(s) identified by the RA-RNTI defined below, in the RA Response window which starts at the subframe that contains the end of the preamble transmission [7] plus three subframes and has length ra-ResponseWindowSize subframes.
It means the earliest time when the network can transmit the RACH response is 3 subframe later from the end of RACH Preamble. Then what is the latest time when the network can transmit it ? It is determined by ra-ResponseWindowSize. This window size can be the number between 0 and 10 in the unit of subframes. This means that the maximum time difference between the end of RACH preamble and RACH Response is only 12 subframes (12 ms) which is pretty tight timing requirement. PRACH Parameters and Physical Meaning < prach-ConfigIndex >
< zeroCorrelationZoneConfig and Highspeedflag >
< prach-FreqOffset >
< rootSequenceIndex >
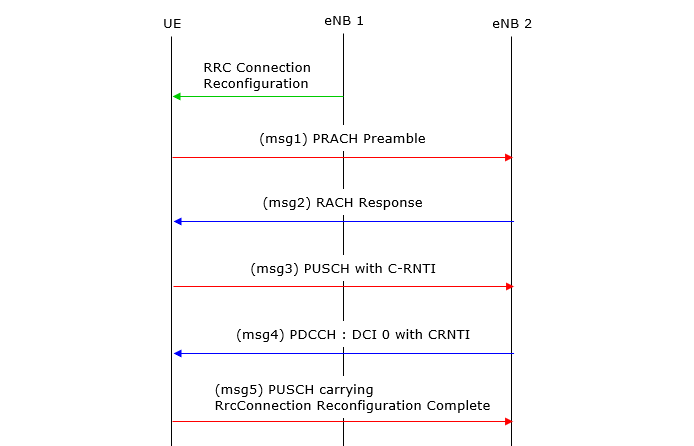
RACH Procedure during Initial Registration – RACH Procedure Summary
Follwing is an example of RACH procedure which happens during the initiail registration. If you will be an engineer who is working on protocol stack development or test case development, you should be very familiar with all the details of this process. Again, we have to know every details of every step without missing anything to be a developer, but of course it is not easy to understand everything at a single shot. So, let’s start with something the most important part, which I think is the details of RACH response. Following diagram shows one example of RACH Response with 5 Mhz bandwidth. We don’t have to memorize the detailed value itself but should be familiar with the data format and understand which part of this bit string means what.
If you decode UL Grant part, you will get the following result. You will notice that the information it carries would be very similar to DCI format 0 which carries Resource Allocation for uplink data. This information in UL Grant in RACH Response message is the resource allocation for msg3 (e.g, RRC Connection Request). Note : This is example of RAR for System BW 5 Mhz. If the sytem BW gets different, you should have different RIV values (if you want to have the same Start_RB, N_RB as in this example) or you will have different Start_RB, N_RB (if you keep RIV as below and just change the system BW)
Let me describe this procedure in verbal form again.
i) UE initiate a Random Access Procedure on the (uplink) Random Access Channel (RACH).(The location of RACH in the frequency/time resource grid the RACH is known to the mobile via the (downlink) Broadcast Channel (BCH). The random access message itself only consists of 6 bits and the main content is a random 5 bit identity)
ii) Network sends a Random Access Response Message(RARM) at a time and location on the Physical Downlink Shared Channel (PDSCH) (The time and location of RARM on PDSCH can be calculated from the time and location the random access message was sent. This message contains the random identity sent by the device, a Cell Radio Network Temporary ID (T_C-RNTI) which will be used for all further bandwidth assignments, and an initial uplink bandwidth assignment) iii) The mobile device then uses the bandwidth assignment to send a short (around 80 bits) RRC Connection Request message which includes it’s identity which has previously been assigned to it by the core network
Only the step i) uses physical-layer processing specifically designed for random access. The remaining steps utilizes the same physical layer processing as used for normal uplink and downlink data transmission
“5.1.4 Random Access Response reception” in “TS36.321” says how to calculate RA_RNTI as follows.
The RA-RNTI associated with the PRACH in which the Random Access Preamble is transmitted, is computed as: RA-RNTI = 1 + t_id + 10 * f_id Where t_id is the index of the first subframe of the specified PRACH (0 <≤ t_id <10), and f_id is the index of the specified PRACH within that subframe, in ascending order of frequency domain (0≤ f_id< 6).
For FDD, f_id is fixed as 0.
Therefore, RA_RNTI is decided by the sending timing (SubFrame) of PRACH Preamble by UE. It means that (the subframe number (number between 0000~0009) of PRACH transmission + 1) is RA-RNTI. It means that UE specifies RA_RNTI by the sending timing (SubFrame) of PRACH Preamble.
An Example of Full RACH Process Following is an example of Full RACH process with a commercialized LTE device and LTE Network Emulator. I would not explain anything in detail. Just check if the following diagram make any sense to you. If it does, I would say you understand all the details that I explained above.
Most part of previous section was about the ideal RACH process, which means that UE send PRACH and Network send RACH Response at the first trial and went through all the way to the end of process at the first trial.
What if UE does not receive RACH Response at the first trial ? What is UE supposed to do in this case ? The answer is simple. Just retry (resend) PRACH. (In this case, UE might not have any Backoff Indicator value which normally transmitted in MAC CE being sent with RAR). There is another case where UE needs to retry PRACH. It is the case where UE received RAR from the network, but the RAPID is not for it (It means that RAR is not for some other UE). In this case, it is highly probable that a Backoff Indicator value is transmitted with RAR to control the PRACH retransmission timing.
Then you would have more question. (“I” in the following description is “UE”) i) When do I have to retry ? (What should be the time delay between the previous transmission and the next transmission ?) ii) Do I have to retransmit the PRACH with the same power as previous one ? Or try with a little bit higher power ? If I have to try with a little bit higher power, how much power do I have to increase ? iii) If I keep failing to receive RACH response, how many time I have to retry ? Do I have to retry until the battery runs out ? or retry only several times and give up ? If I have to give up after a certain amount of retry, exactly how many times do I have to retry ? The answers to all of these questions are provided by the network. The answer (instruction) to question i) is provided by Network via a special RAR MAC PDU called “Backoff Indicator”. The answer to question ii) and iii) are provided by Network via SIB2 as follows. powerRampingStep is the answer to question ii) and preambleTransMax is the answer to question iii). In the following example, powerRampingStep = dB2. It means UE has to increase PRACH power by 2 dB everytime it retries. preambleTransMax = n6. It means UE retries PRACH retransmit only 6 times and then give up. (This is my understanding at least as of now. But trying with real device, I see many cases UE does not give up even after it reaches preambleTransMax. I will get this updated as I find more) | +-radioResourceConfigCommon ::= SEQUENCE | | +-rach-Config ::= SEQUENCE | | | +-preambleInfo ::= SEQUENCE [0] | | | | +-numberOfRA-Preambles ::= ENUMERATED [n52] | | | | +-preamblesGroupAConfig ::= SEQUENCE OPTIONAL:Omit | | | +-powerRampingParameters ::= SEQUENCE | | | | +-powerRampingStep ::= ENUMERATED [dB2] | | | | +-preambleInitialReceivedTargetPower ::= ENUMERATED [dBm-104] | | | +-ra-SupervisionInfo ::= SEQUENCE | | | | +-preambleTransMax ::= ENUMERATED [n6] | | | | +-ra-ResponseWindowSize ::= ENUMERATED [sf10] | | | | +-mac-ContentionResolutionTimer ::= ENUMERATED [sf48] | | | +-maxHARQ-Msg3Tx ::= INTEGER (1..8) [4] Additional Factors : PRACH Config Index (in SIB2) Backoff Indicator (in MAC CE) T-300 (in SIB2) Following is an example of PRACH Retry being observed in a real device. This is the case where UE send PRACH and NW does not send RAR (Yellow cell indicates the timing determined by PRACH Config Index when UE is allowed to send PRACH. See Exactly when and where Network transmit RACH Response . Green cell indicates the timing when UE send PRACH in this specific example)
RACH Process Overview In Diagrams
I have explained long about the RACH process. Now you may ask “What is the trigger that let UE initiate the RACH process ?”. You will see various triggers in 3GTS 36.300 (10.1.5) : Overall description of RACH Process. “Turning on UE” is one of the trigger for sure. And following is another trigger for this process.
< RACH Procedure on Initial Registration > This is basically the same sequence that I explained in previous sections, but I simplified the diagram in previous sections to let reader focused more on messaging part of RACH procedure. In this diagram, you see some additional steps like HARQ ACK, DCI 0 (UL Grant). This flow is more similar to real live network procedure.
< RACH Procedure on Handover – Contention Based >
< RACH Procedure on Handover – NonContention Based >
<RACH Procedure on DL Data Arrival when Out-of-Sync – Non Contention Based >
<RACH Procedure on DL Data Arrival when Out-of-Sync – Contention Based >
<RACH Procedure on UL Data Arrival when Out-of-Sync >
<RACH Procedure on RRC Connection Re-establishment when Out-of-Sync >
3GPP Standard for RACH Process
3GTS 36.300 (10.1.5) : Overall description of RACH Process. Read this first. 3GTS 36.211 (5.7) : RRC Messages and IE (Information Elements) which are involved in RACH process. 3GTS 36.213 (6) : MAC Layer Procedure related to RACH Process.
|









 ,
,





















Power up procedure in GSM
IMSI attach
In a GSM network, when a Mobile Station (MS) is switched on, the International Mobile Subscriber Identity (IMSI) attach procedure is executed. This procedure is required for the Mobile Switching Center(MSC) and Visitor Location Register (VLR) to register the MS in the network. If the MS has changed Location area (LA) while it was powered off the IMSI attach procedure will lead to a Location update.
When the MS is switched on, it searches for a mobile network to connect to. Once the MS identifies its desired network, it sends a message to the network to indicate that it has entered into an idle state. The Visitor Location Register (VLR) checks its database to determine whether there is an existing record of the particular subscriber.
If no record is found, the VLR communicates with the subscriber’s Home Location Register (HLR) and obtains a copy of the subscription information. The obtained information is stored in the database of the VLR. Then an acknowledge message is sent to the MS. Steps for IMSI attach procedure are as follows:
1.The MS will send a Channel Request message to the BSS on the RACH.
2. The BSS responds on the AGCH with an Immediate Assignment message and assigns an SDCCH to the MS.
3. The MS immediately switches to the assigned SDCCH and sends a Location Update Request to the BSS. The MS will send either an IMSI or a TMSI to the BSS.
4. The BSS will acknowledge the message. This acknowledgement only tells the MS that the BTS has received the message, it does not indicate the location update has been processed.
5. The BSS forwards the Location Update Request to the MSC/VLR.
6. The MSC/VLR forwards the IMSI to the HLR and requests verification of the IMSI as well as Authentication Triplets.
7. The HLR will forward the IMSI to the Authentication Center (AuC) and request authentication triplets.
8. The AuC generates the triplets and sends them along with the IMSI, back to the HLR.
9. The HLR validates the IMSI by ensuring it is allowed on the network and is allowed subscriber services. It then forwards the IMSI and Triplets to the MSC/VLR.
10. The MSC/VLR stores the SRES and the Kc and forwards the RAND to the BSS and orders the BSS to authenticate the MS.
11. The BSS sends the MS an Authentication Request message to the MS. The only parameter sent in the message is the RAND.
12. The MS uses the RAND to calculate the SRES and sends the SRES back to the BSS on the SDCCH in an Authentication Response. The BSS forwards the SRES up to the MSC/VLR.
13. The MSC/VLR compares the SRES generated by the AuC with the SRES generated by the MS. If they match, then authentication is completed successfully.
14. The MSC/VLR forwards the Kc for the MS to the BSS. The Kc is NOT sent across the Air Interface to the MS. The BSS stores the Kc and forwards the Set Cipher Mode command to the MS. The CIPH_MOD_CMD only tells the MS which encryption to use (A5/X), no other information is included.
15. The MS immediately switches to cipher mode using the A5 encryption algorithm. All transmissions are now enciphered. It sends a Ciphering Mode Complete message to the BSS.
16. The MSC/VLR sends a Location Updating Accept message to the BSS. It also generates a new TMSI for the MS. TMSI assignment is a function of the VLR. The BSS will either send the TMSI in the LOC_UPD_ACC message or it will send a separate TMSI Reallocation Command message. In both cases, since the Air Interface is now in cipher mode, the TMSI is not compromised.
17. The MS sends a TMSI Reallocation Complete message up to the MSC/VLR.
18. The BSS instructs the MS to go into idle mode by sending it a Channel Release message. The BSS then deassigns the SDCCH.
19. The MSC/VLR sends an Update Location message to the HLR. The HLR records which MSC/VLR the MS is currently in, so it knows which MSC to point to when it is queried for the location of the MS.
IMSI detach
IMSI detach is the process of detaching a MS from the mobile network to which it was connected. The IMSI detach procedure informs the network that the Mobile Station is switched off or is unreachable.
At power-down the MS requests a signaling channel. Once assigned, the MS sends an IMSI detach message to the VLR. When the VLR receives the IMSI detach-message, the corresponding IMSI is marked as detached by setting the IMSI detach flag. The HLR is not informed of this and the VLR does not acknowledge the MS about the IMSI detach.
If the radio link quality is poor when IMSI detach occurs, the VLR may not properly receive the IMSI-detach request. Since an acknowledgment message is not sent to the MS, it does not make further attempts to send IMSI detach messages. Therefore the GSM network considers the MS to be still attached.
Implicit IMSI detach
The GSM air-interface, designated Um, transmits network-specific information on specific broadcast channels. This information includes whether the periodic location update is enabled. If enabled, then the MS must send location update requests at time intervals specified by the network. If the MS is switched off, having not properly completed the IMSI detach procedure, the network will consider the MS as switched off or unreachable if no location update is made. In this situation the VLR performs an implicit IMSI detach.
HOW TO: Get Started With Google Analytics
Whether you built a personal site from the ground up or oversee digital strategy for a huge corporation, many of us are managing a web presence these days.
There are millions of websites out there, and tracking how people are getting to your site and what’s performing well is a must for being competitive in the online market.
Google Analytics makes it easy for anyone managing a site to track and analyze this data. It’s a powerful, free tool that can answer a variety of questions for a wide range of users. Wondering which keywords resonate with visitors? Need insight on what design elements might be turning people away?
Here’s how you can start answering the website questions that have been keeping you awake at night.
Adding the Code

Once you set up your Google Analytics account, you’ll need to implement the code on your website.
Set up a profile for the site you’d like to track and the step-by-step process will generate a unique script that you can add. If you’re using a content management system or blogging platform like WordPress, Blogger or Tumblr, you only need to add the code once to your template or theme. The theme will propagate the code in every post and page you create.
If your site is custom-built, you’ll either need to implement the code on each page manually, or speak to your web developer about how the site generates content.
Copy the JavaScript code from Analytics and paste it just above the </head> tag in your page or template. Adding this code will not affect the look of your site.
What You Can Measure

After you connect your site to Google Analytics, hit “View Report” on the initial screen. This will bring you to the main dashboard. In the left column, you’ll see the various types of data Google Analytics provides:
- Visitors: This shows many things about the people coming to your site, including where they’re located geographically, what language they speak, how often they visit your site and what computers and browsers they use to get there.
- Traffic Sources: Here you’ll find how people got to your site. You can track which sites link to your page or keywords people search to find you.
- Content: This tab gives you insight into specific pages on your site. It can help answer questions about how people enter and exit your pages, as well as which ones are most popular.
- Goals: If you’re aiming for established objectives, reports in the Goals tab will be helpful to you. Here you’ll find data about desired actions from users, including downloads, registrations and purchases.
- Ecommerce: You’ll only need this tab if you’re selling items on your site as it houses all merchandise, transaction and revenue activity information.
These tabs contain subreports that provide insights about specific aspects of your site, including top content and visitor loyalty.
The information you choose to track depends on what curiosities you want to quell. Being in touch with keyword searches can help a site with text-heavy content to boost search rankings, while knowing which products convert best can inspire ecommerce sites to increase visibility of these items.
With Google Analytics, figuring out what you measure is the tough part. It’s how you measure that’s simple.
Setting Up the Dashboard

On the main dashboard, you’ll see a summary of your site’s data. You can customize the dashboard to show whichever reports you decide you want to see upfront. Just click on the type of report you want to see from the left column and hit “Add to Dashboard.” You can then position reports on the dashboard by dragging and dropping, or deleting ones you don’t want.
You can delve deeper into a data set by clicking “View Report” underneath the report graphic on your dashboard. This brings you to the full report on that topic.
Adjusting the Time Range

Be sure to adjust the date range in the upper right-hand corner before analyzing information from your reports. It defaults to a month-long range, ending the day prior to the day you’re viewing the report. (For example, on May 18, you’d see reports spanning April 17 to May 17.) Click on the date range box and a calendar will pop up. You can adjust it to track information quarterly, weekly, daily, or whatever timeframe works best for you.
If you want to compare date ranges, hit “Comparison” underneath the “Date Range” field. This will bring up a second calendar for you to adjust based on what time periods you want to consider, such as weekend to weekend or the first Tuesday of the month vs. the last Tuesday of the month.
Data Tables and Visualizations

Many of the reports in Google Analytics, such as pageviews and conversion rates, contain linear graphs that present data for the topic and date range you’ve selected. When mousing over the dots on the line, you’ll see measurements for that day, week or hour.
You can change the metric you want to visualize by clicking the tab above the graph on the left. Here you’ll also have the option to compare two metrics against each other. When you’re not comparing date ranges, you can compare against the site average. This is particularly helpful if you’ve laid out goals, as you can compare site activity to conversion goals. When comparing, a second line (gray) will appear for the variable over the graph with the original metric line (blue), making it easy to see how you’re stacking up.
Beneath the graph, you’ll see more data laid out with summaries and scorecards prominently displaying important overall metrics, such as pages per visit and time on site. Most reports have three different tabs in the top left above the scorecards: Site Usage, Goal Conversion and Ecommerce.
More granular measurements of these data sets can be found in a table below. You can visualize the table in a pie chart or a bar graph by clicking the icons just above and to the right of the scorecards. Table information can be sorted in ascending or descending order by clicking on the column heading you want to reorganize. To increase or decrease the number of results displayed, click the “Show Rows” drop down menu at the bottom right of the report. The default is 10 and you can show up to 500 results per page.
You can also refine data with the “Find Source” box at the bottom left of the report. Enter keywords relevant to your search such as “source” or “keyword” and select “containing” or “excluding” to reveal more specific information.
If you’re unsure of what a specific measurement means, click the question mark next to it and an explanation bubble will pop up.
Sharing Reports
You’ll find an email button at the top of all reports, just beneath the title. You can send the email immediately, schedule a recurring report email or add the report to an existing pre-scheduled email. If you’re presenting the report, you can export it as a PDF (recommended), XML, CSV or TSV file.
Source: Mash
5 Unknown Keyword Research Tips To Boost Your Online Traffic
Are you having a hard time finding out which keywords to target for your SEO and PPC campaigns?
Let me show you 5 Keyword Research Tips that will end your Keyword research problems.
1. Swipe your Competitor’s Keyword Research
Why not let your “established” and “authority” competitors do the keyword research for you?
You can ethically “swipe” your competitor’s keywords by using these Google’s Free Keyword Tool.
Use Google Keyword Tool
Here’s what you need to do.
List at least 5 top competitors that are ranking in the top results for your targeted terms or niche.
Let me use “Keyword Research Tips” as an example of a keyword/keyword theme that I would like to target.
I will then Paste the Top 5 URLs that are ranking for this term in Google Keyword Tool’s Website Box
Change your location and language based on your targeted demographic. Choose Global and English if you are targeting a worldwide audience.
Choose exact match or phrase match as keyword match types. I prefer to use phrase matches because it can help me find “hidden long tail keywords” later on.
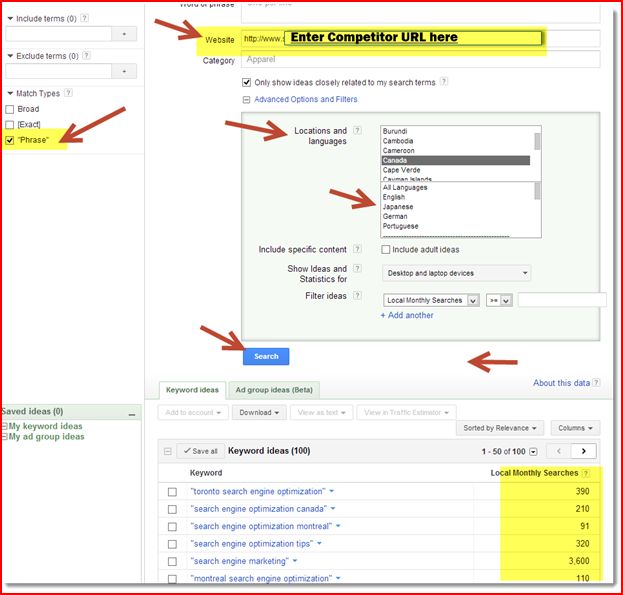
The great thing about this strategy is that you’ll immediately see the search volumes for the keywords you’ve chosen.
Select keywords that you think will be relevant to your niche and group them together to create tightly themed set of keywords.
2. Find hidden long tail keywords in the phrase-match/exact match difference
This strategy can help you uncover hidden long tail keywords that might be less competitive than most keywords.
The secret here is the difference between Phrase Match and Exact Match Search volumes.
Google Keyword Tool usually shows the Phrase match and Exact match search volumes, but they seldom release related long tail keywords to target for your SEO and PPC campaigns.
Basically, you’ll need to find the phrase match and exact match search volume of a particular keyword.
If there’s a huge difference between the search volumes, then you have a winning keyword.
Try to find the “missing long tail keywords” through Google instant searches or try some PPC advertising to drive some impressions and clicks which will help you identify these “hidden keyword opportunities”.
Here’s an example of what I mean:
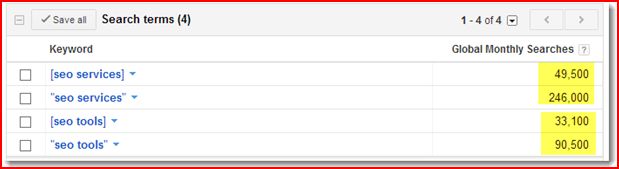
SEO Tools (in Google Global Search)
“seo tools” (phrase match) = 90,500
[seo tools] (exact match) = 33,100
“SEO Tools” Phrase Match/Exact Match Difference = 57,400
SEO Services (in Google Global Search)
“seo services” (phrase match) = 246,000
[seo services] (exact match) = 49,500
“SEO Services” Phrase Match/Exact Match Difference = 196,500
Obviously the bigger opportunity lies in optimizing for the term “SEO Services” since it has 196,500 hidden long tail keywords.
These hidden long tail keywords includes:
“seo services canada”
“seo services toronto”
and more
The idea here is to find keywords that have huge differences between the search volumes of the phrase and exact match and create content around those keywords.
3. Blog on upcoming events and product launches
Monitor competitor product releases, industry updates and industry news.
If you can rank and optimize for keywords that are not being searched today, but will be highly searched in the future, then you’re in a great position to generate tons of traffic for that search term.
Here are just a few examples:
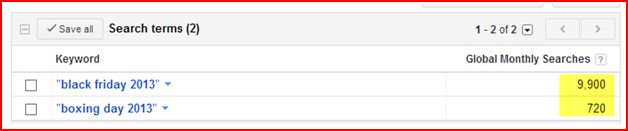
Date Based Searches
Black Friday 2013
Boxing Day 2013
Product launches
[Product name] launch
[Product name] review
[Product name] information
Basically, these strategy relies on anticipating keywords that will be highly searched in the future. These keywords are easier to rank in the search engines because no one is still optimizing for these terms.
4. Add geo-targeted search terms to your Keywords for Local Search
If you are promoting a local business, or you offer products and services to a local demographic, adding geo-location keywords for search can help you rank a lot faster than regular keywords.
Here’s another example.
If you want to optimize for “Seo Services” it might take you several months, or even years to outrank your competition.
Instead try adding geo locations to your keywords:

“Seo services Canada”
“Seo services Toronto”
These keywords might have less search volumes, but they are highly targeted and more likely to convert than the Fat Head keywords.
5. Mine your existing Google Analytics Data for Long Tail Keywords that you might have missed
Do you know that you can find tons of keyword research data from your existing Google Analytics data? Of course this will only work for old websites with some organic or paid search traffic before. Using Google Analytics Regular Filters you can create a list of long tail keywords.
You can filter keywords with 3,4,5,6,7 or more keywords in the search phrase. This will help you find content ideas, keywords opportunities that you might want to include in your next blog post.
I’ve created a Google Analytics Dashboard to help you find these keywords quickly. Make sure you’re signed in to Google Analytics and Click here to Copy my SEO Dashboard. And there you have it, 5 Unconventional Keyword Research Tips that can help solve your Keyword research problems.
50 Tools to Jumpstart Your Content Marketing Efforts
Companies are defined today by their unique story. Anyone can sell a product but why buy that product over another? Creating radio spots and billboard ads are not enough in today’s consumer centric marketplace to connect with customers, it’s content that helps craft a story about your business, drive home your unique value and inform potential customers why they should buy your product or service over others.
Jumpstarting your content marketing efforts can be an uphill battle if you don’t have the right tools in place to get the job done. It’s time to think like a journalist and a marketer to offer your audiences content that is both useful and entertaining, similar to the value a publication brings to its readers. Here are 50 tools to help bolster your content marketing strategy for the future:
Tools for Content Discovery & Ideas
1. SPUN for iPhone – SPUN is an app for the iPhone with a beautiful interface that curates the best of the web from millions of websites, Tumblrs, YouTube channels, online magazine and blogs.
2. Feedly – Since Google Reader has shut down July 1st, Feedly has become the best option for RSS having grown to 7 million users in recent months. Add your favorite blogs and websites to start filling up your feed with content.
3. Pulse – Purchased by LinkedIn not too long ago, Pulse is an app that serves as a RSS feed from other sources allowing users to curate based on their interests and topics of choice.
4. Quora – The popular social network is a platform for question and answer discussions. Identify trends from consistently asked questions to inform your content creation efforts.
5. Trapit – This content discovery app personalizes the content feed based on your passions and interests, designed just for the iPad. The app learns from your feedback, giving you better content each time it’s used.
6. Inbound.org – Use Inbound.org to find great content from the world of inbound marketing from other marketers, curated by the community.
7. Paper.li – Browse curated online newspapers and newsletters from millions of sources across the web. Look thru the Paper.li newsstand for staff picks of newspapers on a variety of engaging topics.
8. Alltop – Content is indexed from a variety of top publications, categorized by topics like Work, Health, Culture, Interests, Tech, People, Good, News, Geos and Sports.
9. Twitter – Search trending topics on Twitter to see what is popular worldwide or in a specific region to gain insights on what content to develop. Also search hashtags that are relevant to your expertise and industry to research what subjects of our interest to your existing audience and potential audiences.
10. Reddit – Discover what’s trending worldwide on Reddit for content inspiration on a variety of topics from across the web. Observing which headlines are more effective on Reddit can bring insights to the subject of your next article, infographic, video or other type of content.
Tools for Marketing & Distribution
11. Buffer – Use Buffer to schedule your content across Facebook, LinkedIn and Twitter for posting at the best times optimized for your account or at the times of your choosing. Buffer helps streamline the process of distributing content to each channel quickly and effectively.
12. Slideshare – An often overlooked tool for content marketing, create a deck to draw attention to a resource or service on your website. Like this deck on YouTube Virality, that drove 20,000+ views to the creator’s content.
13. Yoast – The best search engine optimization plugin for WordPress that helps bolster your website and its content to its full potential with all the major search engines. It simplifies the process making it easier for website owners of all levels keep their web properties inline with SEO best practices.
14. MailChimp – MailChimp is one of the easiest email marketing platforms to use to market your content to your email list. Don’t have an email list? The exclusive content your business will create and distribute using this platform will help fuel new subscribers to your email list.
15. Promoted Posts on Facebook – Facebook advertising can bolster the visibility of your content in the newsfeed far greater than it would reach on its own organically. Pay per post to get your content featured in front of a larger audience on Facebook with your fans and non-fans alike.
16. Inbound Writer – This content optimization application lets your business monitor topics of interest, understand your readers and reach your readers by providing insights on what type of content to create that match’s the passions of your audience.
17. PRWeb – Use this syndication platform to send SEO optimized press releases about your most valuable content to 30,000 journalists, 250,000 opt-in news subscribers and to the 3 million monthly visitors on PRWeb.com. The platform is easy to use and allows many effective tools to create your press release, distribute it and monitor its success.
18. Followgen – Targeting tool that allows a business to find a meaningful audience on the social web with the goal of getting your content in front of the right audience. It’s a strong fusion of a targeting system and social advertising.
19. Tweriod – Twitter tool that helps determine the best time to tweet your content for your business. The tool gets your content in front of more tweeters and comes in the form of a free simple report that outlines the best times to tweet.
20. Bundlr – Create topic pages with photos, videos, tweets, articles and more to distribute with everyone in your network. The “Bundle This!” plugin allows users to clip content from their browser as they browse, making it quick and easy to bundle your content with other quality sources of information.
Tools for Organization
21. Trello – A completely free tool for organizing everything from media to ideas on neatly organized cards. Streamline your content ideas and collaborate with your other team members by gathering votes on particular cards to have real time feedback on the best content to pursue further.
22. Evernote – Evernote is the multi-use organizational platform that’s widely known as the way to remember everything from your business to personal life. Use Evernote to keep track of your content ideas and editorial calendar from the computer or your mobile phone on the go.
23. Google Calendar – One of Google’s many helpful tools, the Google Calendar is an effective way to organize and collaborate on your editorial and production calendar for your company’s content.
24. IFTTT – Put the Internet to work for you by creating custom recipes that increase the productivity across all of your web applications and platforms by making them work together more effectively.
25. Wunderlist – Create beautiful and more importantly, powerful lists that outline your content strategy, content ideas from your desktop at work or on mobile while you’re on the go.
26. Pinterest – Use Pinterest to organize your resources, the content from others and your favorite websites for content marketing inspiration. Utilize the secret board function if there’s anything your team doesn’t wish to curate to the public.
27. Pocket – Save videos, articles and other helpful resources away to check out later. The Pocket app helps keep your favorite resources organized from apps like Twitter, Flipboard, Pulse, Zite and 300+ apps.
28. Remember That Milk – Manage all your tasks with this app that seamlessly integrates with Gmail, Outlook, Twitter, Evernote, Google Calendar and more. Think of this app as the to-do list reinvented.
29. Harvest – The time tracking tool can help keep your content marketing efforts on schedule with accurate and effective software to help make smarter decisions for your business. Understanding where your time is spent and on what tasks will help strengthen your content creation efforts.
30. MindNode – Map out your brainstorm sessions and ideas to better understand what’s on track and what’s not working for your content strategy using the MindNode app. Think about your content as ideas that merely need to be flesh out, connect the dots with this visual experience for the iPhone, iPad or Mac.
Tools for Content Creation
31. Meme Generator – If you need to add a comical spin to your content, then look to add a meme from this easy to use web resource. For inspiration, check out which memes generated by the service are gaining traction on the web.
32. Visual.ly – Create stunning inforgraphics and data visualizations using Visual.ly from their marketplace of infographic experts and designers. Explore the 30,000+ infographics already created on the website for inspiration for your content marketing.
33. Google Keyword Tool – Using the Google keyword tool you’ll be able to search for the right pairings of keywords to use in the headlines and body of your articles that are more often searched in Google. Don’t take this data as the final say on your headline, but use this info has an approximation of the search traffic certain keywords are currently receiving.
34. GIMP – Create visuals for your content using GIMP, which is a free, simplified Photoshop like software. Including images in your posts is very crucial since 40% of people will respond better to visual information than plain text.
35. Resize.it – An online image resizing tool to bring the images you’ve created or curated to the right dimensions for publishing. Resize.it is a helpful resource for non-technical users to fix their images for use in their articles, e-books and PDF’s.
36. Issuu – A visually striking tool for creating online magazines and lookbooks with both free and paid versions depending on your content needs and budget.
37. Utrak – Utrak is a tool that allows you to embed a simple web-based poll into your content. Adding a poll to your content is another way to make it more engaging for readers.
38. Embedded Tweets – Add live tweets to your online content to add credibility to a topic and interactive aspect to your article or website. Tweets display with expanded media like photos, videos, and article summaries, and also include real-time retweet and favorite counts. When embedded, Tweets are interactive and enable your readers to follow the Tweet author, and reply, retweet, favorite all directly from the page.
39. Thinglink – Tag images to make them more engaging with links to music, video, text, images, Twitter, Facebook, shops and more using Thinglink. This tool allows readers to comment on images and follow image channels of creative users. ThingLink images are also shareable, and embeddable, with a click to Facebook, Twitter, Tumblr and email.
40. PowToon – Create animated videos and presentations with PowToon to add a commercial quality experience to your original content.
41. UberFlip – Optimize your PDF’s to add social widgets, audio and video elements to make the content both interactive and measurable.
Tools for Writing
42. Contently – A platform that allows businesses to work with high-quality freelance writers that also handles the payment and management of the editorial process.
43. Skyword – This tool offers businesses different levels of content creation services with their access to 20,000 writers, as well as an exclusive partnership with Thomson Reuters for business intelligence and Bigstock Imagery for stock images.
44. Textbroker – Textbroker is a content creation service offering a quick turnaround on articles, press releases, written snippets for websites and more from a database of authors.
45. Compendium – The Compendium platform empowers publishers with the tools necessary to plan, produce, publish, promote and measure their content marketing all from one dashboard.
46. Shareist – Shareist is editorial platform for small to medium size businesses that helps with the entire content marketing life cycle. The tool helps your business capture content from around the web, easily incorporating text, links, videos, images and more. Export this content for use anywhere, such as email newsletters, and eBooks.
47. Lingospot – The Lingospot software offers automated content marketing for your website, automatically updating the content throughout your web properties. With flexible control of the level of automation to use on each of your pages, businesses can create thousands of dynamically refreshing topic pages.
48. NewsCred – An enterprise content development platform that offers businesses 2,500 sources, millions of full text articles, images and video to help bolster their content strategy. The platform also streamlines the legal and billing process of using the content owned by other publications, companies and individuals.
49. XYDO – Create and curate editorial content to meet your online and email marketing needs with XYDO. Integrates smoothly with MailChimp and Constant Contact to amplify your messaging with trending and relevant content.
50. Brafton – The Brafton platform offers content marketing, as well as search engine optimization, social media marketing and content analytics services to ensure the content created on your company’s behalf will perform well on the social web and with the right audience.
BONUS – The Best Infographics on Content Marketing Tools
The Content Marketing Landscape via Content AMP
What’s Your Content Marketing Challenge via Curata
The Content of Integrity in the Age of the Consumer via Econsultancy
What content marketing tools has your business found the most effective? Are there any tools that should be added to the list? Share your thoughts in the comments below.
About the Author: Brian Honigman is a freelance writer, content marketer and social media consultant.
Source: KM
Designing a Content Strategy to Destroy Your SEO Nemesis
Do you do SEO for a brand involved in a straight fight with another company? It’s pretty common for brands to become fixated on one particular competitor; I’ve seen entire marketing strategies geared towards beating another brand, rather than hitting a specific revenue target.
While some would argue it’s unhealthy to define any market as a two-horse race (especially in today’s fast-changing world), some marketing leaders like to do it to motivate their staff. They believe that you can better channel your team’s competitive spirit when your staff can relate to what / who the “enemy” is.
Pros and cons aside, there’s a good chance you will eventually work for a company that thinks this way. In the long term maybe you’ll be able to convince them to broaden their competitive focus, but in the meantime, wouldn’t it be awesome to deliver a content strategy specifically to them that is designed to help them build market share at the expense of their SEO nemesis?
How to Design Your Content Strategy
To do this I’m going to use the following model to visualize the content landscape:

By using the following methodology you should be able to build a content strategy, which enables you to:
- Expand your visibility into areas currently considered business threats.
- Understand in detail the dogfight between you and your competitor, as well as how to gain the upper hand in this battle.
- Expand your visibility through a focus on where your audience is being underserved.
The methodology pits two companies against each other across an unlimited number of keywords, using search volume and click curve data to understand each brand’s current reach. It then classifies each keyword so that they can be slotted into the model above. We can then understand the relative size of each part of the content landscape and tell the client what topics they should be publishing on in future.
If you don’t care about the methodology there is a template you can download here.
Use Keyword & Click Curve Data
You will need as many relevant keywords as you can lay your hands on, grouped by topic. For each keyword you will need:
- Your organic rank.
- Your competitor’s organic rank.
- Exact match local search volume.
You will also need click curve data in a separate table. If you don’t have the data to build your own click curve, there is a ready made one here.
Once you have that data in two tables you’ll first need to estimate current traffic for both you and your competitor from each keyword.
Do this by multiplying the exact match search volume by the CTR figure corresponding to current rank (simple vlookup to retrieve this).
Determine Traffic Differences
Work out the percentage difference between your traffic and your competitors. If your competitor receives more traffic for a keyword, the figure should be negative.
Use if statements to ensure that where both brands receive no traffic a figure of 0 is returned, or a large positive figure (I use 1000 percent) if your brand receives a lot of traffic and your competitor receives none at all. You need to use these statements because percentage change involves division and if 0 figures you will have errors returned.
Classify Each Keyword
We can classify each keyword based on our content landscape model using nested if statements. The criteria is described below:

Once we have applied your nested if statement across all keywords and related each keyword to a place on the content landscape we can use filters to quickly isolate the keywords we’re interested in.
Get Visual
Use pivot tables to quickly show the number of searches in each sector, and other details, such as how much traffic each brand is getting within the dogfight sector, or the size of the business success sector relative to the business threat sector.
Here your keyword grouping comes into their own as you can visualize both the overall content landscape and the landscape for just a small subset of similar terms.
I’ve yet to build a Venn diagram or bubble chart that can show the relative sizes of each sector of the content landscape; I’d love to know if you can do this in the comments!
Despite the lack of a proportionally sized Venn, you have been able to visualize for your client how well their content serves the consumers need, as well as indicating which topics they should be focusing their content creation on in order to take the SEO fight to their main competitor and steal their SEO market share.
Prioritize Terms
As a next step, you could prioritize the most important terms, a process which enables you to make the task of content ideation much more disciplined and less prone to becoming one endless, unfocused brainstorm.
Simply take all the opportunity and threat keywords from above and estimate how difficult it will be to improve ranking for these keywords using a tool like SEOmoz’s keyword difficulty estimator.
You can then multiply the difficulty score by the search volume for each keyword to give a weighted score for how important each keyword is.
Brainstorm
Following this step my recommendation would be to hold a brainstorming session focused on the topics identified as a priority in the graph above, but that’s a topic that could take up a series of posts in itself!
Summary
For this piece I’ll leave you with a template for the process outlined above: there are a lot of possibilities for making this process even better; for instance, you could quickly use the click curve to model what the content landscape would look like if you managed to alter your clients visibility, leading to a forecast of how market share might change based on your content strategy.
All in all, I hope this template will enable you to compare and contrast your content strategy and SEO performance with that of your SEO nemesis and come up with a way to vanquish your most dreaded foe once and for all!
Source: SEW
SEO Failure? Where to Point the Fingers
Many companies as well as clients have a difficult time accepting that they may have been the reason for an SEO failure. In most situations, the blame goes immediately to the SEO company, department, or expert, and rightfully so. These are the people in charge of making sure SEO succeeds, so these are the people that will most likely take the blame (and be happy to do it). However, it’s important to realize that just because they are forced (in a sense) to take the blame doesn’t mean they are actually to blame.
The Client vs. The Expert vs. Google: Who Is Really to Blame for an SEO Failure?
If you want to be an informed client or informed SEO expert, it’s important to see all different sides to a failure and consider all different outcomes. Below explains the three different parties that are most likely to be at fault and some of the reasons and instances that might put them in that position:
The Client: Yes, it’s possible!
The clients are always right; except when they’re wrong. Even when it comes to SEO, it’s important that the client is involved in the campaign. It’s completely OK if a client doesn’t understand SEO, but there are a few things a client needs to do in order to make sure the efforts are successful. A few times when a failure really is the client’s fault include:
- Changes Weren’t Made. In most cases, an SEO firm or expert will make recommendations about how to optimize the website. Oftentimes, these recommendations have to do with changing content slightly to include certain keywords or changing something in the Meta data. If the client completely ignores this advice and decides not to ask its developers to do anything, that’s really not the fault of the agency/expert that worked hard to offer suggestions.
- A Plan Wasn’t Discussed. Even if a client doesn’t really understand SEO and how it works, he/she surely has some idea about the goals wanted for the company. These goals should be used by an SEO agency and a plan should be laid out ahead of time. The client needs to be paying attention to every step of the process and reading reports that the SEO will send.
- Stop Efforts Too Soon. When all is said and done, it is usually the client who can stop the SEO efforts for the company. If the client simply too impatient to wait for results (sometimes six months are needed) and pulls the plug too early, it wasn’t for lack of trying on the agency’s part. It’s easy to be impatient in SEO, but that will surely be any campaigns killer.
The SEO Company: Often the problem, but most likely to take the blame either way.
As you would assume, this is where most of the problems lie. SEO departments or experts are the ones who have the most control when it comes to a campaign, so there are several things that could go wrong:
- Black Hat Tactics. Any black hat tactic that is used—cloaking, keyword stuffing, duplicate content, etc.—is entirely the fault of the SEO department. You can learn more about black hat tactics here.
- Poor Communication. Those in charge of SEO need to make sure that they are communicating with the client. The client might not always know that they should be asking about a particular method or approach, so it’s your job to keep them completely in the loop. This will often spark questions and will help keep that partnership between client and agency/expert strong. If an SEO simply decides not to communicate a change with the client and the client doesn’t like it in the future, that’s the SEO’s fault.
- General Laziness. This might seem obvious, but as with anything, an SEO agency or expert can get lazy and just not feel like helping. It’s as simple as that.
- False Guarantees. Many SEOs give false guarantees such as “Number 1 Ranking in One Month Or Your Money Back.” If an agency couldn’t deliver on this, it’s their own fault because they should know that guarantees are not possible in SEO.
There are of course more detailed reasons that could occur based on the specific situation, but these are just a few of the most common ways that an SEO company might be the reason for a campaign’s failure.
The Search Engine: They don’t mean any harm.
Sometimes SEO campaigns fail because of the search engines. Search engines only rock an current SEO campaigns in order to improve search results for users, so they don’t mean any harm, but they can cause harm because of a few reasons:
- Algorithm Updates. An SEO could be optimizing a website for certain keywords and doing great, but the minute a Panda or Penguin update hits you might find the website back at the bottom. If the SEOs are building links and optimizing correctly the website should be able to bypass the very negative effects of an algorithm update, but some changes might shake the campaign whether you’ve been following the rules or not, and all anyone can really do at this point is just try and recover.
- Negative SEO. It is the SEOs responsibility to take action against negative SEO through the disavow links tool and reconsideration requests. Now negative SEO is the fault of competitors or from spam sites that are trying to bring the website down, so you really can’t blame the search engines for this one. However, it is the search engines who are going to take the action of bringing a site down because of negative SEO (particularly if they missed a spam site or directory). This is the perfect example of the “no hard feelings” mentality.
Analyzing Why It Matters and How to Deal With the Blame Game
Understanding who is to blame can help an SEO agency/expert and a client work together to create the most successful campaign possible for that company. If a client knows when he/she would be in the wrong, he/she can try and prevent this from happening altogether. If it does happen, then no time will need to be wasted yelling at the SEOs. The exact same can be said for SEOs when they are in the wrong. Be up front and honest so that the relationship between SEO and client can move forward.
Have you ever had an instance where you haven’t felt like you were at fault when it came to an SEO blunder? What did you do in response (and who were you in the scenario)? Let us know your story and give us your thoughts in the comments below.
Photo Credit: patentpracticeliability.com
Source: SEJ
How to start a Start-up
March 2005
(This essay is derived from a talk at the Harvard Computer Society.)
You need three things to create a successful startup: to start with good people, to make something customers actually want, and to spend as little money as possible. Most startups that fail do it because they fail at one of these. A startup that does all three will probably succeed.
And that’s kind of exciting, when you think about it, because all three are doable. Hard, but doable. And since a startup that succeeds ordinarily makes its founders rich, that implies getting rich is doable too. Hard, but doable.
If there is one message I’d like to get across about startups, that’s it. There is no magically difficult step that requires brilliance to solve.
The Idea
In particular, you don’t need a brilliant idea to start a startup around. The way a startup makes money is to offer people better technology than they have now. But what people have now is often so bad that it doesn’t take brilliance to do better.
Google’s plan, for example, was simply to create a search site that didn’t suck. They had three new ideas: index more of the Web, use links to rank search results, and have clean, simple web pages with unintrusive keyword-based ads. Above all, they were determined to make a site that was good to use. No doubt there are great technical tricks within Google, but the overall plan was straightforward. And while they probably have bigger ambitions now, this alone brings them a billion dollars a year. [1]
There are plenty of other areas that are just as backward as search was before Google. I can think of several heuristics for generating ideas for startups, but most reduce to this: look at something people are trying to do, and figure out how to do it in a way that doesn’t suck.
For example, dating sites currently suck far worse than search did before Google. They all use the same simple-minded model. They seem to have approached the problem by thinking about how to do database matches instead of how dating works in the real world. An undergrad could build something better as a class project. And yet there’s a lot of money at stake. Online dating is a valuable business now, and it might be worth a hundred times as much if it worked.
An idea for a startup, however, is only a beginning. A lot of would-be startup founders think the key to the whole process is the initial idea, and from that point all you have to do is execute. Venture capitalists know better. If you go to VC firms with a brilliant idea that you’ll tell them about if they sign a nondisclosure agreement, most will tell you to get lost. That shows how much a mere idea is worth. The market price is less than the inconvenience of signing an NDA.
Another sign of how little the initial idea is worth is the number of startups that change their plan en route. Microsoft’s original plan was to make money selling programming languages, of all things. Their current business model didn’t occur to them until IBM dropped it in their lap five years later.
Ideas for startups are worth something, certainly, but the trouble is, they’re not transferrable. They’re not something you could hand to someone else to execute. Their value is mainly as starting points: as questions for the people who had them to continue thinking about.
What matters is not ideas, but the people who have them. Good people can fix bad ideas, but good ideas can’t save bad people.
People
What do I mean by good people? One of the best tricks I learned during our startup was a rule for deciding who to hire. Could you describe the person as an animal? It might be hard to translate that into another language, but I think everyone in the US knows what it means. It means someone who takes their work a little too seriously; someone who does what they do so well that they pass right through professional and cross over into obsessive.
What it means specifically depends on the job: a salesperson who just won’t take no for an answer; a hacker who will stay up till 4:00 AM rather than go to bed leaving code with a bug in it; a PR person who will cold-call New York Times reporters on their cell phones; a graphic designer who feels physical pain when something is two millimeters out of place.
Almost everyone who worked for us was an animal at what they did. The woman in charge of sales was so tenacious that I used to feel sorry for potential customers on the phone with her. You could sense them squirming on the hook, but you knew there would be no rest for them till they’d signed up.
If you think about people you know, you’ll find the animal test is easy to apply. Call the person’s image to mind and imagine the sentence “so-and-so is an animal.” If you laugh, they’re not. You don’t need or perhaps even want this quality in big companies, but you need it in a startup.
For programmers we had three additional tests. Was the person genuinely smart? If so, could they actually get things done? And finally, since a few good hackers have unbearable personalities, could we stand to have them around?
That last test filters out surprisingly few people. We could bear any amount of nerdiness if someone was truly smart. What we couldn’t stand were people with a lot of attitude. But most of those weren’t truly smart, so our third test was largely a restatement of the first.
When nerds are unbearable it’s usually because they’re trying too hard to seem smart. But the smarter they are, the less pressure they feel to act smart. So as a rule you can recognize genuinely smart people by their ability to say things like “I don’t know,” “Maybe you’re right,” and “I don’t understand x well enough.”
This technique doesn’t always work, because people can be influenced by their environment. In the MIT CS department, there seems to be a tradition of acting like a brusque know-it-all. I’m told it derives ultimately from Marvin Minsky, in the same way the classic airline pilot manner is said to derive from Chuck Yeager. Even genuinely smart people start to act this way there, so you have to make allowances.
It helped us to have Robert Morris, who is one of the readiest to say “I don’t know” of anyone I’ve met. (At least, he was before he became a professor at MIT.) No one dared put on attitude around Robert, because he was obviously smarter than they were and yet had zero attitude himself.
Like most startups, ours began with a group of friends, and it was through personal contacts that we got most of the people we hired. This is a crucial difference between startups and big companies. Being friends with someone for even a couple days will tell you more than companies could ever learn in interviews. [2]
It’s no coincidence that startups start around universities, because that’s where smart people meet. It’s not what people learn in classes at MIT and Stanford that has made technology companies spring up around them. They could sing campfire songs in the classes so long as admissions worked the same.
If you start a startup, there’s a good chance it will be with people you know from college or grad school. So in theory you ought to try to make friends with as many smart people as you can in school, right? Well, no. Don’t make a conscious effort to schmooze; that doesn’t work well with hackers.
What you should do in college is work on your own projects. Hackers should do this even if they don’t plan to start startups, because it’s the only real way to learn how to program. In some cases you may collaborate with other students, and this is the best way to get to know good hackers. The project may even grow into a startup. But once again, I wouldn’t aim too directly at either target. Don’t force things; just work on stuff you like with people you like.
Ideally you want between two and four founders. It would be hard to start with just one. One person would find the moral weight of starting a company hard to bear. Even Bill Gates, who seems to be able to bear a good deal of moral weight, had to have a co-founder. But you don’t want so many founders that the company starts to look like a group photo. Partly because you don’t need a lot of people at first, but mainly because the more founders you have, the worse disagreements you’ll have. When there are just two or three founders, you know you have to resolve disputes immediately or perish. If there are seven or eight, disagreements can linger and harden into factions. You don’t want mere voting; you need unanimity.
In a technology startup, which most startups are, the founders should include technical people. During the Internet Bubble there were a number of startups founded by business people who then went looking for hackers to create their product for them. This doesn’t work well. Business people are bad at deciding what to do with technology, because they don’t know what the options are, or which kinds of problems are hard and which are easy. And when business people try to hire hackers, they can’t tell which ones are good. Even other hackers have a hard time doing that. For business people it’s roulette.
Do the founders of a startup have to include business people? That depends. We thought so when we started ours, and we asked several people who were said to know about this mysterious thing called “business” if they would be the president. But they all said no, so I had to do it myself. And what I discovered was that business was no great mystery. It’s not something like physics or medicine that requires extensive study. You just try to get people to pay you for stuff.
I think the reason I made such a mystery of business was that I was disgusted by the idea of doing it. I wanted to work in the pure, intellectual world of software, not deal with customers’ mundane problems. People who don’t want to get dragged into some kind of work often develop a protective incompetence at it. Paul Erdos was particularly good at this. By seeming unable even to cut a grapefruit in half (let alone go to the store and buy one), he forced other people to do such things for him, leaving all his time free for math. Erdos was an extreme case, but most husbands use the same trick to some degree.
Once I was forced to discard my protective incompetence, I found that business was neither so hard nor so boring as I feared. There are esoteric areas of business that are quite hard, like tax law or the pricing of derivatives, but you don’t need to know about those in a startup. All you need to know about business to run a startup are commonsense things people knew before there were business schools, or even universities.
If you work your way down the Forbes 400 making an x next to the name of each person with an MBA, you’ll learn something important about business school. After Warren Buffett, you don’t hit another MBA till number 22, Phil Knight, the CEO of Nike. There are only 5 MBAs in the top 50. What you notice in the Forbes 400 are a lot of people with technical backgrounds. Bill Gates, Steve Jobs, Larry Ellison, Michael Dell, Jeff Bezos, Gordon Moore. The rulers of the technology business tend to come from technology, not business. So if you want to invest two years in something that will help you succeed in business, the evidence suggests you’d do better to learn how to hack than get an MBA. [3]
There is one reason you might want to include business people in a startup, though: because you have to have at least one person willing and able to focus on what customers want. Some believe only business people can do this– that hackers can implement software, but not design it. That’s nonsense. There’s nothing about knowing how to program that prevents hackers from understanding users, or about not knowing how to program that magically enables business people to understand them.
If you can’t understand users, however, you should either learn how or find a co-founder who can. That is the single most important issue for technology startups, and the rock that sinks more of them than anything else.
What Customers Want
It’s not just startups that have to worry about this. I think most businesses that fail do it because they don’t give customers what they want. Look at restaurants. A large percentage fail, about a quarter in the first year. But can you think of one restaurant that had really good food and went out of business?
Restaurants with great food seem to prosper no matter what. A restaurant with great food can be expensive, crowded, noisy, dingy, out of the way, and even have bad service, and people will keep coming. It’s true that a restaurant with mediocre food can sometimes attract customers through gimmicks. But that approach is very risky. It’s more straightforward just to make the food good.
It’s the same with technology. You hear all kinds of reasons why startups fail. But can you think of one that had a massively popular product and still failed?
In nearly every failed startup, the real problem was that customers didn’t want the product. For most, the cause of death is listed as “ran out of funding,” but that’s only the immediate cause. Why couldn’t they get more funding? Probably because the product was a dog, or never seemed likely to be done, or both.
When I was trying to think of the things every startup needed to do, I almost included a fourth: get a version 1 out as soon as you can. But I decided not to, because that’s implicit in making something customers want. The only way to make something customers want is to get a prototype in front of them and refine it based on their reactions.
The other approach is what I call the “Hail Mary” strategy. You make elaborate plans for a product, hire a team of engineers to develop it (people who do this tend to use the term “engineer” for hackers), and then find after a year that you’ve spent two million dollars to develop something no one wants. This was not uncommon during the Bubble, especially in companies run by business types, who thought of software development as something terrifying that therefore had to be carefully planned.
We never even considered that approach. As a Lisp hacker, I come from the tradition of rapid prototyping. I would not claim (at least, not here) that this is the right way to write every program, but it’s certainly the right way to write software for a startup. In a startup, your initial plans are almost certain to be wrong in some way, and your first priority should be to figure out where. The only way to do that is to try implementing them.
Like most startups, we changed our plan on the fly. At first we expected our customers to be Web consultants. But it turned out they didn’t like us, because our software was easy to use and we hosted the site. It would be too easy for clients to fire them. We also thought we’d be able to sign up a lot of catalog companies, because selling online was a natural extension of their existing business. But in 1996 that was a hard sell. The middle managers we talked to at catalog companies saw the Web not as an opportunity, but as something that meant more work for them.
We did get a few of the more adventurous catalog companies. Among them was Frederick’s of Hollywood, which gave us valuable experience dealing with heavy loads on our servers. But most of our users were small, individual merchants who saw the Web as an opportunity to build a business. Some had retail stores, but many only existed online. And so we changed direction to focus on these users. Instead of concentrating on the features Web consultants and catalog companies would want, we worked to make the software easy to use.
I learned something valuable from that. It’s worth trying very, very hard to make technology easy to use. Hackers are so used to computers that they have no idea how horrifying software seems to normal people. Stephen Hawking’s editor told him that every equation he included in his book would cut sales in half. When you work on making technology easier to use, you’re riding that curve up instead of down. A 10% improvement in ease of use doesn’t just increase your sales 10%. It’s more likely to double your sales.
How do you figure out what customers want? Watch them. One of the best places to do this was at trade shows. Trade shows didn’t pay as a way of getting new customers, but they were worth it as market research. We didn’t just give canned presentations at trade shows. We used to show people how to build real, working stores. Which meant we got to watch as they used our software, and talk to them about what they needed.
No matter what kind of startup you start, it will probably be a stretch for you, the founders, to understand what users want. The only kind of software you can build without studying users is the sort for which you are the typical user. But this is just the kind that tends to be open source: operating systems, programming languages, editors, and so on. So if you’re developing technology for money, you’re probably not going to be developing it for people like you. Indeed, you can use this as a way to generate ideas for startups: what do people who are not like you want from technology?
When most people think of startups, they think of companies like Apple or Google. Everyone knows these, because they’re big consumer brands. But for every startup like that, there are twenty more that operate in niche markets or live quietly down in the infrastructure. So if you start a successful startup, odds are you’ll start one of those.
Another way to say that is, if you try to start the kind of startup that has to be a big consumer brand, the odds against succeeding are steeper. The best odds are in niche markets. Since startups make money by offering people something better than they had before, the best opportunities are where things suck most. And it would be hard to find a place where things suck more than in corporate IT departments. You would not believe the amount of money companies spend on software, and the crap they get in return. This imbalance equals opportunity.
If you want ideas for startups, one of the most valuable things you could do is find a middle-sized non-technology company and spend a couple weeks just watching what they do with computers. Most good hackers have no more idea of the horrors perpetrated in these places than rich Americans do of what goes on in Brazilian slums.
Start by writing software for smaller companies, because it’s easier to sell to them. It’s worth so much to sell stuff to big companies that the people selling them the crap they currently use spend a lot of time and money to do it. And while you can outhack Oracle with one frontal lobe tied behind your back, you can’t outsell an Oracle salesman. So if you want to win through better technology, aim at smaller customers. [4]
They’re the more strategically valuable part of the market anyway. In technology, the low end always eats the high end. It’s easier to make an inexpensive product more powerful than to make a powerful product cheaper. So the products that start as cheap, simple options tend to gradually grow more powerful till, like water rising in a room, they squash the “high-end” products against the ceiling. Sun did this to mainframes, and Intel is doing it to Sun. Microsoft Word did it to desktop publishing software like Interleaf and Framemaker. Mass-market digital cameras are doing it to the expensive models made for professionals. Avid did it to the manufacturers of specialized video editing systems, and now Apple is doing it to Avid. Henry Ford did it to the car makers that preceded him. If you build the simple, inexpensive option, you’ll not only find it easier to sell at first, but you’ll also be in the best position to conquer the rest of the market.
It’s very dangerous to let anyone fly under you. If you have the cheapest, easiest product, you’ll own the low end. And if you don’t, you’re in the crosshairs of whoever does.
Raising Money
To make all this happen, you’re going to need money. Some startups have been self-funding– Microsoft for example– but most aren’t. I think it’s wise to take money from investors. To be self-funding, you have to start as a consulting company, and it’s hard to switch from that to a product company.
Financially, a startup is like a pass/fail course. The way to get rich from a startup is to maximize the company’s chances of succeeding, not to maximize the amount of stock you retain. So if you can trade stock for something that improves your odds, it’s probably a smart move.
To most hackers, getting investors seems like a terrifying and mysterious process. Actually it’s merely tedious. I’ll try to give an outline of how it works.
The first thing you’ll need is a few tens of thousands of dollars to pay your expenses while you develop a prototype. This is called seed capital. Because so little money is involved, raising seed capital is comparatively easy– at least in the sense of getting a quick yes or no.
Usually you get seed money from individual rich people called “angels.” Often they’re people who themselves got rich from technology. At the seed stage, investors don’t expect you to have an elaborate business plan. Most know that they’re supposed to decide quickly. It’s not unusual to get a check within a week based on a half-page agreement.
We started Viaweb with $10,000 of seed money from our friend Julian. But he gave us a lot more than money. He’s a former CEO and also a corporate lawyer, so he gave us a lot of valuable advice about business, and also did all the legal work of getting us set up as a company. Plus he introduced us to one of the two angel investors who supplied our next round of funding.
Some angels, especially those with technology backgrounds, may be satisfied with a demo and a verbal description of what you plan to do. But many will want a copy of your business plan, if only to remind themselves what they invested in.
Our angels asked for one, and looking back, I’m amazed how much worry it caused me. “Business plan” has that word “business” in it, so I figured it had to be something I’d have to read a book about business plans to write. Well, it doesn’t. At this stage, all most investors expect is a brief description of what you plan to do and how you’re going to make money from it, and the resumes of the founders. If you just sit down and write out what you’ve been saying to one another, that should be fine. It shouldn’t take more than a couple hours, and you’ll probably find that writing it all down gives you more ideas about what to do.
For the angel to have someone to make the check out to, you’re going to have to have some kind of company. Merely incorporating yourselves isn’t hard. The problem is, for the company to exist, you have to decide who the founders are, and how much stock they each have. If there are two founders with the same qualifications who are both equally committed to the business, that’s easy. But if you have a number of people who are expected to contribute in varying degrees, arranging the proportions of stock can be hard. And once you’ve done it, it tends to be set in stone.
I have no tricks for dealing with this problem. All I can say is, try hard to do it right. I do have a rule of thumb for recognizing when you have, though. When everyone feels they’re getting a slightly bad deal, that they’re doing more than they should for the amount of stock they have, the stock is optimally apportioned.
There is more to setting up a company than incorporating it, of course: insurance, business license, unemployment compensation, various things with the IRS. I’m not even sure what the list is, because we, ah, skipped all that. When we got real funding near the end of 1996, we hired a great CFO, who fixed everything retroactively. It turns out that no one comes and arrests you if you don’t do everything you’re supposed to when starting a company. And a good thing too, or a lot of startups would never get started. [5]
It can be dangerous to delay turning yourself into a company, because one or more of the founders might decide to split off and start another company doing the same thing. This does happen. So when you set up the company, as well as as apportioning the stock, you should get all the founders to sign something agreeing that everyone’s ideas belong to this company, and that this company is going to be everyone’s only job.
[If this were a movie, ominous music would begin here.]
While you’re at it, you should ask what else they’ve signed. One of the worst things that can happen to a startup is to run into intellectual property problems. We did, and it came closer to killing us than any competitor ever did.
As we were in the middle of getting bought, we discovered that one of our people had, early on, been bound by an agreement that said all his ideas belonged to the giant company that was paying for him to go to grad school. In theory, that could have meant someone else owned big chunks of our software. So the acquisition came to a screeching halt while we tried to sort this out. The problem was, since we’d been about to be acquired, we’d allowed ourselves to run low on cash. Now we needed to raise more to keep going. But it’s hard to raise money with an IP cloud over your head, because investors can’t judge how serious it is.
Our existing investors, knowing that we needed money and had nowhere else to get it, at this point attempted certain gambits which I will not describe in detail, except to remind readers that the word “angel” is a metaphor. The founders thereupon proposed to walk away from the company, after giving the investors a brief tutorial on how to administer the servers themselves. And while this was happening, the acquirers used the delay as an excuse to welch on the deal.
Miraculously it all turned out ok. The investors backed down; we did another round of funding at a reasonable valuation; the giant company finally gave us a piece of paper saying they didn’t own our software; and six months later we were bought by Yahoo for much more than the earlier acquirer had agreed to pay. So we were happy in the end, though the experience probably took several years off my life.
Don’t do what we did. Before you consummate a startup, ask everyone about their previous IP history.
Once you’ve got a company set up, it may seem presumptuous to go knocking on the doors of rich people and asking them to invest tens of thousands of dollars in something that is really just a bunch of guys with some ideas. But when you look at it from the rich people’s point of view, the picture is more encouraging. Most rich people are looking for good investments. If you really think you have a chance of succeeding, you’re doing them a favor by letting them invest. Mixed with any annoyance they might feel about being approached will be the thought: are these guys the next Google?
Usually angels are financially equivalent to founders. They get the same kind of stock and get diluted the same amount in future rounds. How much stock should they get? That depends on how ambitious you feel. When you offer x percent of your company for y dollars, you’re implicitly claiming a certain value for the whole company. Venture investments are usually described in terms of that number. If you give an investor new shares equal to 5% of those already outstanding in return for $100,000, then you’ve done the deal at a pre-money valuation of $2 million.
How do you decide what the value of the company should be? There is no rational way. At this stage the company is just a bet. I didn’t realize that when we were raising money. Julian thought we ought to value the company at several million dollars. I thought it was preposterous to claim that a couple thousand lines of code, which was all we had at the time, were worth several million dollars. Eventually we settled on one millon, because Julian said no one would invest in a company with a valuation any lower. [6]
What I didn’t grasp at the time was that the valuation wasn’t just the value of the code we’d written so far. It was also the value of our ideas, which turned out to be right, and of all the future work we’d do, which turned out to be a lot.
The next round of funding is the one in which you might deal with actual venture capital firms. But don’t wait till you’ve burned through your last round of funding to start approaching them. VCs are slow to make up their minds. They can take months. You don’t want to be running out of money while you’re trying to negotiate with them.
Getting money from an actual VC firm is a bigger deal than getting money from angels. The amounts of money involved are larger, millions usually. So the deals take longer, dilute you more, and impose more onerous conditions.
Sometimes the VCs want to install a new CEO of their own choosing. Usually the claim is that you need someone mature and experienced, with a business background. Maybe in some cases this is true. And yet Bill Gates was young and inexperienced and had no business background, and he seems to have done ok. Steve Jobs got booted out of his own company by someone mature and experienced, with a business background, who then proceeded to ruin the company. So I think people who are mature and experienced, with a business background, may be overrated. We used to call these guys “newscasters,” because they had neat hair and spoke in deep, confident voices, and generally didn’t know much more than they read on the teleprompter.
We talked to a number of VCs, but eventually we ended up financing our startup entirely with angel money. The main reason was that we feared a brand-name VC firm would stick us with a newscaster as part of the deal. That might have been ok if he was content to limit himself to talking to the press, but what if he wanted to have a say in running the company? That would have led to disaster, because our software was so complex. We were a company whose whole m.o. was to win through better technology. The strategic decisions were mostly decisions about technology, and we didn’t need any help with those.
This was also one reason we didn’t go public. Back in 1998 our CFO tried to talk me into it. In those days you could go public as a dogfood portal, so as a company with a real product and real revenues, we might have done well. But I feared it would have meant taking on a newscaster– someone who, as they say, “can talk Wall Street’s language.”
I’m happy to see Google is bucking that trend. They didn’t talk Wall Street’s language when they did their IPO, and Wall Street didn’t buy. And now Wall Street is collectively kicking itself. They’ll pay attention next time. Wall Street learns new languages fast when money is involved.
You have more leverage negotiating with VCs than you realize. The reason is other VCs. I know a number of VCs now, and when you talk to them you realize that it’s a seller’s market. Even now there is too much money chasing too few good deals.
VCs form a pyramid. At the top are famous ones like Sequoia and Kleiner Perkins, but beneath those are a huge number you’ve never heard of. What they all have in common is that a dollar from them is worth one dollar. Most VCs will tell you that they don’t just provide money, but connections and advice. If you’re talking to Vinod Khosla or John Doerr or Mike Moritz, this is true. But such advice and connections can come very expensive. And as you go down the food chain the VCs get rapidly dumber. A few steps down from the top you’re basically talking to bankers who’ve picked up a few new vocabulary words from reading Wired. (Does your product use XML?) So I’d advise you to be skeptical about claims of experience and connections. Basically, a VC is a source of money. I’d be inclined to go with whoever offered the most money the soonest with the least strings attached.
You may wonder how much to tell VCs. And you should, because some of them may one day be funding your competitors. I think the best plan is not to be overtly secretive, but not to tell them everything either. After all, as most VCs say, they’re more interested in the people than the ideas. The main reason they want to talk about your idea is to judge you, not the idea. So as long as you seem like you know what you’re doing, you can probably keep a few things back from them. [7]
Talk to as many VCs as you can, even if you don’t want their money, because a) they may be on the board of someone who will buy you, and b) if you seem impressive, they’ll be discouraged from investing in your competitors. The most efficient way to reach VCs, especially if you only want them to know about you and don’t want their money, is at the conferences that are occasionally organized for startups to present to them.
Not Spending It
When and if you get an infusion of real money from investors, what should you do with it? Not spend it, that’s what. In nearly every startup that fails, the proximate cause is running out of money. Usually there is something deeper wrong. But even a proximate cause of death is worth trying hard to avoid.
During the Bubble many startups tried to “get big fast.” Ideally this meant getting a lot of customers fast. But it was easy for the meaning to slide over into hiring a lot of people fast.
Of the two versions, the one where you get a lot of customers fast is of course preferable. But even that may be overrated. The idea is to get there first and get all the users, leaving none for competitors. But I think in most businesses the advantages of being first to market are not so overwhelmingly great. Google is again a case in point. When they appeared it seemed as if search was a mature market, dominated by big players who’d spent millions to build their brands: Yahoo, Lycos, Excite, Infoseek, Altavista, Inktomi. Surely 1998 was a little late to arrive at the party.
But as the founders of Google knew, brand is worth next to nothing in the search business. You can come along at any point and make something better, and users will gradually seep over to you. As if to emphasize the point, Google never did any advertising. They’re like dealers; they sell the stuff, but they know better than to use it themselves.
The competitors Google buried would have done better to spend those millions improving their software. Future startups should learn from that mistake. Unless you’re in a market where products are as undifferentiated as cigarettes or vodka or laundry detergent, spending a lot on brand advertising is a sign of breakage. And few if any Web businesses are so undifferentiated. The dating sites are running big ad campaigns right now, which is all the more evidence they’re ripe for the picking. (Fee, fie, fo, fum, I smell a company run by marketing guys.)
We were compelled by circumstances to grow slowly, and in retrospect it was a good thing. The founders all learned to do every job in the company. As well as writing software, I had to do sales and customer support. At sales I was not very good. I was persistent, but I didn’t have the smoothness of a good salesman. My message to potential customers was: you’d be stupid not to sell online, and if you sell online you’d be stupid to use anyone else’s software. Both statements were true, but that’s not the way to convince people.
I was great at customer support though. Imagine talking to a customer support person who not only knew everything about the product, but would apologize abjectly if there was a bug, and then fix it immediately, while you were on the phone with them. Customers loved us. And we loved them, because when you’re growing slow by word of mouth, your first batch of users are the ones who were smart enough to find you by themselves. There is nothing more valuable, in the early stages of a startup, than smart users. If you listen to them, they’ll tell you exactly how to make a winning product. And not only will they give you this advice for free, they’ll pay you.
We officially launched in early 1996. By the end of that year we had about 70 users. Since this was the era of “get big fast,” I worried about how small and obscure we were. But in fact we were doing exactly the right thing. Once you get big (in users or employees) it gets hard to change your product. That year was effectively a laboratory for improving our software. By the end of it, we were so far ahead of our competitors that they never had a hope of catching up. And since all the hackers had spent many hours talking to users, we understood online commerce way better than anyone else.
That’s the key to success as a startup. There is nothing more important than understanding your business. You might think that anyone in a business must, ex officio, understand it. Far from it. Google’s secret weapon was simply that they understood search. I was working for Yahoo when Google appeared, and Yahoo didn’t understand search. I know because I once tried to convince the powers that be that we had to make search better, and I got in reply what was then the party line about it: that Yahoo was no longer a mere “search engine.” Search was now only a small percentage of our page views, less than one month’s growth, and now that we were established as a “media company,” or “portal,” or whatever we were, search could safely be allowed to wither and drop off, like an umbilical cord.
Well, a small fraction of page views they may be, but they are an important fraction, because they are the page views that Web sessions start with. I think Yahoo gets that now.
Google understands a few other things most Web companies still don’t. The most important is that you should put users before advertisers, even though the advertisers are paying and users aren’t. One of my favorite bumper stickers reads “if the people lead, the leaders will follow.” Paraphrased for the Web, this becomes “get all the users, and the advertisers will follow.” More generally, design your product to please users first, and then think about how to make money from it. If you don’t put users first, you leave a gap for competitors who do.
To make something users love, you have to understand them. And the bigger you are, the harder that is. So I say “get big slow.” The slower you burn through your funding, the more time you have to learn.
The other reason to spend money slowly is to encourage a culture of cheapness. That’s something Yahoo did understand. David Filo’s title was “Chief Yahoo,” but he was proud that his unofficial title was “Cheap Yahoo.” Soon after we arrived at Yahoo, we got an email from Filo, who had been crawling around our directory hierarchy, asking if it was really necessary to store so much of our data on expensive RAID drives. I was impressed by that. Yahoo’s market cap then was already in the billions, and they were still worrying about wasting a few gigs of disk space.
When you get a couple million dollars from a VC firm, you tend to feel rich. It’s important to realize you’re not. A rich company is one with large revenues. This money isn’t revenue. It’s money investors have given you in the hope you’ll be able to generate revenues. So despite those millions in the bank, you’re still poor.
For most startups the model should be grad student, not law firm. Aim for cool and cheap, not expensive and impressive. For us the test of whether a startup understood this was whether they had Aeron chairs. The Aeron came out during the Bubble and was very popular with startups. Especially the type, all too common then, that was like a bunch of kids playing house with money supplied by VCs. We had office chairs so cheap that the arms all fell off. This was slightly embarrassing at the time, but in retrospect the grad-studenty atmosphere of our office was another of those things we did right without knowing it.
Our offices were in a wooden triple-decker in Harvard Square. It had been an apartment until about the 1970s, and there was still a claw-footed bathtub in the bathroom. It must once have been inhabited by someone fairly eccentric, because a lot of the chinks in the walls were stuffed with aluminum foil, as if to protect against cosmic rays. When eminent visitors came to see us, we were a bit sheepish about the low production values. But in fact that place was the perfect space for a startup. We felt like our role was to be impudent underdogs instead of corporate stuffed shirts, and that is exactly the spirit you want.
An apartment is also the right kind of place for developing software. Cube farms suck for that, as you’ve probably discovered if you’ve tried it. Ever notice how much easier it is to hack at home than at work? So why not make work more like home?
When you’re looking for space for a startup, don’t feel that it has to look professional. Professional means doing good work, not elevators and glass walls. I’d advise most startups to avoid corporate space at first and just rent an apartment. You want to live at the office in a startup, so why not have a place designed to be lived in as your office?
Besides being cheaper and better to work in, apartments tend to be in better locations than office buildings. And for a startup location is very important. The key to productivity is for people to come back to work after dinner. Those hours after the phone stops ringing are by far the best for getting work done. Great things happen when a group of employees go out to dinner together, talk over ideas, and then come back to their offices to implement them. So you want to be in a place where there are a lot of restaurants around, not some dreary office park that’s a wasteland after 6:00 PM. Once a company shifts over into the model where everyone drives home to the suburbs for dinner, however late, you’ve lost something extraordinarily valuable. God help you if you actually start in that mode.
If I were going to start a startup today, there are only three places I’d consider doing it: on the Red Line near Central, Harvard, or Davis Squares (Kendall is too sterile); in Palo Alto on University or California Aves; and in Berkeley immediately north or south of campus. These are the only places I know that have the right kind of vibe.
The most important way to not spend money is by not hiring people. I may be an extremist, but I think hiring people is the worst thing a company can do. To start with, people are a recurring expense, which is the worst kind. They also tend to cause you to grow out of your space, and perhaps even move to the sort of uncool office building that will make your software worse. But worst of all, they slow you down: instead of sticking your head in someone’s office and checking out an idea with them, eight people have to have a meeting about it. So the fewer people you can hire, the better.
During the Bubble a lot of startups had the opposite policy. They wanted to get “staffed up” as soon as possible, as if you couldn’t get anything done unless there was someone with the corresponding job title. That’s big company thinking. Don’t hire people to fill the gaps in some a priori org chart. The only reason to hire someone is to do something you’d like to do but can’t.
If hiring unnecessary people is expensive and slows you down, why do nearly all companies do it? I think the main reason is that people like the idea of having a lot of people working for them. This weakness often extends right up to the CEO. If you ever end up running a company, you’ll find the most common question people ask is how many employees you have. This is their way of weighing you. It’s not just random people who ask this; even reporters do. And they’re going to be a lot more impressed if the answer is a thousand than if it’s ten.
This is ridiculous, really. If two companies have the same revenues, it’s the one with fewer employees that’s more impressive. When people used to ask me how many people our startup had, and I answered “twenty,” I could see them thinking that we didn’t count for much. I used to want to add “but our main competitor, whose ass we regularly kick, has a hundred and forty, so can we have credit for the larger of the two numbers?”
As with office space, the number of your employees is a choice between seeming impressive, and being impressive. Any of you who were nerds in high school know about this choice. Keep doing it when you start a company.
Should You?
But should you start a company? Are you the right sort of person to do it? If you are, is it worth it?
More people are the right sort of person to start a startup than realize it. That’s the main reason I wrote this. There could be ten times more startups than there are, and that would probably be a good thing.
I was, I now realize, exactly the right sort of person to start a startup. But the idea terrified me at first. I was forced into it because I was a Lisp hacker. The company I’d been consulting for seemed to be running into trouble, and there were not a lot of other companies using Lisp. Since I couldn’t bear the thought of programming in another language (this was 1995, remember, when “another language” meant C++) the only option seemed to be to start a new company using Lisp.
I realize this sounds far-fetched, but if you’re a Lisp hacker you’ll know what I mean. And if the idea of starting a startup frightened me so much that I only did it out of necessity, there must be a lot of people who would be good at it but who are too intimidated to try.
So who should start a startup? Someone who is a good hacker, between about 23 and 38, and who wants to solve the money problem in one shot instead of getting paid gradually over a conventional working life.
I can’t say precisely what a good hacker is. At a first rate university this might include the top half of computer science majors. Though of course you don’t have to be a CS major to be a hacker; I was a philosophy major in college.
It’s hard to tell whether you’re a good hacker, especially when you’re young. Fortunately the process of starting startups tends to select them automatically. What drives people to start startups is (or should be) looking at existing technology and thinking, don’t these guys realize they should be doing x, y, and z? And that’s also a sign that one is a good hacker.
I put the lower bound at 23 not because there’s something that doesn’t happen to your brain till then, but because you need to see what it’s like in an existing business before you try running your own. The business doesn’t have to be a startup. I spent a year working for a software company to pay off my college loans. It was the worst year of my adult life, but I learned, without realizing it at the time, a lot of valuable lessons about the software business. In this case they were mostly negative lessons: don’t have a lot of meetings; don’t have chunks of code that multiple people own; don’t have a sales guy running the company; don’t make a high-end product; don’t let your code get too big; don’t leave finding bugs to QA people; don’t go too long between releases; don’t isolate developers from users; don’t move from Cambridge to Route 128; and so on. [8] But negative lessons are just as valuable as positive ones. Perhaps even more valuable: it’s hard to repeat a brilliant performance, but it’s straightforward to avoid errors. [9]
The other reason it’s hard to start a company before 23 is that people won’t take you seriously. VCs won’t trust you, and will try to reduce you to a mascot as a condition of funding. Customers will worry you’re going to flake out and leave them stranded. Even you yourself, unless you’re very unusual, will feel your age to some degree; you’ll find it awkward to be the boss of someone much older than you, and if you’re 21, hiring only people younger rather limits your options.
Some people could probably start a company at 18 if they wanted to. Bill Gates was 19 when he and Paul Allen started Microsoft. (Paul Allen was 22, though, and that probably made a difference.) So if you’re thinking, I don’t care what he says, I’m going to start a company now, you may be the sort of person who could get away with it.
The other cutoff, 38, has a lot more play in it. One reason I put it there is that I don’t think many people have the physical stamina much past that age. I used to work till 2:00 or 3:00 AM every night, seven days a week. I don’t know if I could do that now.
Also, startups are a big risk financially. If you try something that blows up and leaves you broke at 26, big deal; a lot of 26 year olds are broke. By 38 you can’t take so many risks– especially if you have kids.
My final test may be the most restrictive. Do you actually want to start a startup? What it amounts to, economically, is compressing your working life into the smallest possible space. Instead of working at an ordinary rate for 40 years, you work like hell for four. And maybe end up with nothing– though in that case it probably won’t take four years.
During this time you’ll do little but work, because when you’re not working, your competitors will be. My only leisure activities were running, which I needed to do to keep working anyway, and about fifteen minutes of reading a night. I had a girlfriend for a total of two months during that three year period. Every couple weeks I would take a few hours off to visit a used bookshop or go to a friend’s house for dinner. I went to visit my family twice. Otherwise I just worked.
Working was often fun, because the people I worked with were some of my best friends. Sometimes it was even technically interesting. But only about 10% of the time. The best I can say for the other 90% is that some of it is funnier in hindsight than it seemed then. Like the time the power went off in Cambridge for about six hours, and we made the mistake of trying to start a gasoline powered generator inside our offices. I won’t try that again.
I don’t think the amount of bullshit you have to deal with in a startup is more than you’d endure in an ordinary working life. It’s probably less, in fact; it just seems like a lot because it’s compressed into a short period. So mainly what a startup buys you is time. That’s the way to think about it if you’re trying to decide whether to start one. If you’re the sort of person who would like to solve the money problem once and for all instead of working for a salary for 40 years, then a startup makes sense.
For a lot of people the conflict is between startups and graduate school. Grad students are just the age, and just the sort of people, to start software startups. You may worry that if you do you’ll blow your chances of an academic career. But it’s possible to be part of a startup and stay in grad school, especially at first. Two of our three original hackers were in grad school the whole time, and both got their degrees. There are few sources of energy so powerful as a procrastinating grad student.
If you do have to leave grad school, in the worst case it won’t be for too long. If a startup fails, it will probably fail quickly enough that you can return to academic life. And if it succeeds, you may find you no longer have such a burning desire to be an assistant professor.
If you want to do it, do it. Starting a startup is not the great mystery it seems from outside. It’s not something you have to know about “business” to do. Build something users love, and spend less than you make. How hard is that?
Source: Paul Graham
Why You Shouldn’t Outsource Content
The internet can be broken down into two separate groups – those who create content and those who consume it. Those who create it have more social shares, influence, revenue, Google love, etc. We get it. Content is king and limes are green.
There’s obviously a need to crank out content on a large scale, which has led to the use of automatic content generation for mass distribution. I’m aware of instant article software that is capable of producing hundreds, even thousands, of unique, content-rich web pages in a matter of minutes. But like Shania used to say, “that don’t impress me much.”
Yeah it saves time, but a marketing strategy built solely upon automatic content generation will not be sustainable. Maybe a decade ago, but not today. We’re witnessing more and more the value Google is placing on content readability, social shares, and authorship; all things you must earn as a content creator.
So what do you lose by outsourcing content to other folks or having it auto generated?
Quality Suffers
In order to create the kind of content that takes your online business to new heights, it has to be correct, creative and contagious. These qualities are difficult to come by via outsourcing and nearly impossible to obtain through tools alone.
It’s no secret that Google is weighing heavily on social shares and interactions. Millions of people stand ready to magnify your great content to unheard of levels. However, nobody shares unreadable spam (definitely not black and white animals), so relying on content generation tools won’t get you far on that front.

Outsourced content lacks that smoothness that only comes through industry experience. Freelance writers, bloggers, content strategists and the likes usually possess strong writing skills, but just because an article is well written doesn’t mean it’s great content.
You Lose Your Writer’s Voice
Interestingly, outsourced writing jobs often get divvied out among a group of writers. This could spell trouble for you, leaving significant holes, false assumptions and possible inaccuracies in your product. But more importantly, you lose your writer’s voice.
This pertains more to editorialized pieces where your writer’s style and voice really shines through, rather than encyclopedic type content that’s dry and factual. But your writer’s voice is your pride! You’ve worked hard on it. It’s your style. Your personality comes through to the reader in ways they really appreciate. Your writer’s voice helps establish your culture.
Outsourcing Can Be Viable
If writing is a weak spot or you simply don’t have the time, outsource work to just one writer so that your voice is at least consistent. Then provide that writer with samples so that he/she has something from which to deduce your writing style. A skilled writer will be able to use their skills with your voice.
In Summary
Not everyone has the resources or even the desire to write content themselves. For some, outsourcing is viable. The bottom line here is that it’s important to understand the risks you take by outsourcing content to other folks and by using content generation tools like content reoptimization software, autoblogging, article spinning and the such. They may not be as effective as you think.
Image courtesy of Christian Barmala
Source: SEJ
SEO Reporting & Metrics: How to Prove Progress
It’s the beginning of the month and it’s again time to report to your clients or your boss on the SEO progress made last month. It’s time to justify your SEO strategy, your efforts and yourself. Sound familiar?
With the challenging landscape of SEO comes the challenging landscape of SEO reporting, and I’m not just talking about merging SEO data sources into one Excel file and adding a logo to try to make it look professional, presentable, and understandable. I’m talking about how to make all the data points and metrics indicate real progress, and more importantly meet your clients’ or boss’ expectations.
Since the way we do SEO has changed, the way we report on it must change too. Effectively setting up the reporting metrics to prove progress may make the difference between meeting the clients’ expectations or not.
SEO reporting should answer these questions for your client:
- Are our efforts helping us reach our organic search goals?
- What SEO tasks were completed last month in relation to our goals?
- What impact did these efforts have on the web presence for organic search?
- What new opportunities were identified to optimize for organic search?
- Are there any new competitive threats?
So how do you set up your SEO data, metrics and reporting to prove this progress and set the stage for the subsequent month? How do you set up your SEO team for success?
Follow these four steps with month-end reporting in mind for more successful SEO outcomes.
1. Set Expectations
Clarify what SEO is compared to what it isn’t.
Most of us know that SEO is not just about ranking first in Google for the preferred set of keywords, but the people you have to report to might not be on the same page. Set the expectation early in the relationship that SEO is more than just rank, and that SEO ranking data isn’t the be all and end all of SEO reporting. Setting this expectation is key.
SEO is the on-going process of discovering and uncovering highly converting unbranded keyword phrases that are driving organic search traffic and conversion – then taking action across the web presence to improve upon impact and create new impact. Impact in the form of increased organic search traffic and conversions, expansion of keywords you are being found for, content footprint index, etc.
Metrics that demonstrate the impact of your SEO efforts include:
- Organic traffic/visits
- Organic position
- Conversions by keyword
- On-site and off-site indexed pages

2. Set Goals & Benchmarks
Quantifying the starting point will help clarify the final outcomes.
Agreeing on and setting goals for the SEO project is obviously key and will help maintain focus. Including those goals in the monthly SEO report will remind your client or your boss of what the overall reason for the investment is after the project gets going.
Let’s face it, it’s easy to forget why we thought SEO was important. To prove impact, setting goals and benchmarking the current web presence is necessary.
A couple examples of realistic goals to work toward are:
- “To increase traffic from organic search by 20 percent over the next two months.”
- “To triple the number of highly converting unbranded keywords.”
To help demonstrate progress with these goals, benchmarking certain metrics and including the benchmark values in the monthly report is key.
SEO metrics to benchmark to demonstrate progress and achievement of the agreed upon goals include:
- Organic search traffic both as a percentage of overall website traffic and the number of unique visitors.
- Backlink diversity.
- Unbranded keywords found in anchor text.
- Social signals by social channel.
- Number of unbranded keywords driving traffic.
- Number of unbranded keywords driving conversions.
- Number of indexed pages.
3. Set up Goals and Conversions in Analytics
Doing SEO without goals and conversions set up in analytics is a fruitless exercise.
If SEO is about understanding highly converting unbranded keywords that are driving organic search traffic and conversions, then doing SEO without goals and conversions set up in analytics makes this task next to impossible.
Whether you’re using Google Analytics, Coremetrics, Omniture, or another analytics system, it is important to set up even some simple goals. Think about the website in question and what you consider a successful visit to be.
More advanced goals can be set up as you get to know the website and the behavior of the visitor, but if you’re looking for some simple goals to get started in order to understand successful keywords here are two:
- Time on Page: If the time the visitor stays on the page is greater than 2 or 3 minutes then this can be considered a conversion. One can conclude that whichever keyword the visitor searched on to get to the site matched the content on the page plus they stayed a reasonable amount of time to read the content.
- 2+ Pages Visited: Similarly to Time on Page, number of pages visited can help indicate that the visitor is engaged with the content. Knowing the keyword they searched on to arrive at the page will help to discover new unbranded keywords that ought to be optimized for.
Make time every week to discover and uncover new highly converting keywords. Identify them in your monthly report, discuss them with your client as well as the opportunities you have identified to create on-site and off-site content for these keywords. This is an upsell opportunity for SEO services.
4. Set Metrics & Drive Action Items
Metrics without action items are useless.
SEO is an ongoing process and you want to keep your client engaged, so continuing to discover opportunities through the metrics and demonstrating that more content writing can be done will keep their investment top of mind and ongoing.
Here are some metrics that will help with continuous action items:
Keywords by Position Sorted by Highest to Lowest Converter
Action items:
- Perform additional keyword research to identify other related search terms including variations and longer-tail terms. How might these keywords be included into on-site or off-site content to test engagement and understand if the keyword(s) in question will perform well?
- Identify other pages on the website that are ranking beyond page one for the keywords in question. What can be done to further optimize these pages to improve rankings?
- Obtain additional budget to write content and report on metrics.
New Content Being Indexed and Ranked
- Identify new on-site and off-site pages that are being ranked and indexed. Which pages can be optimized further? If conversions increase, then perhaps an entire content campaign can be created around this keyword. Once this is identified, obtain additional budget to create and execute on this content campaign and report on the metrics.
Summary
SEO reporting should be considered an art rather than a science. Monthly SEO reporting deserves a conversation with your client or boss to help describe the opportunities for optimization that you see in the metrics.
Setting the expectation that reporting is more than just presenting rank data will help to create a relationship that is open to exploring opportunities to optimize based on strong metrics around keyword visits and conversions.

{kind=link}
{kind=link}